ML Data Products
Our data ecosystems contain ML data products that are essential to core business requirements and decisions. The data’s origin, impact path, quality, and freshness are all critical to the success of these products. When the performance of ML models degrades, democratized access to metadata and the ability to consume it quickly to make informed decisions can help to recover more rapidly. MeshLens makes it easy to integrate ML data products into the Data Mesh view, providing deep insights into these products.
This tutorial illustrates how to integrate ML data products with MeshLens. We start with a reference architecture that uses ML Orchestration with Step Functions and data transformation with Glue jobs. We then perform metadata augmentation to integrate with MeshLens and view our catalog.
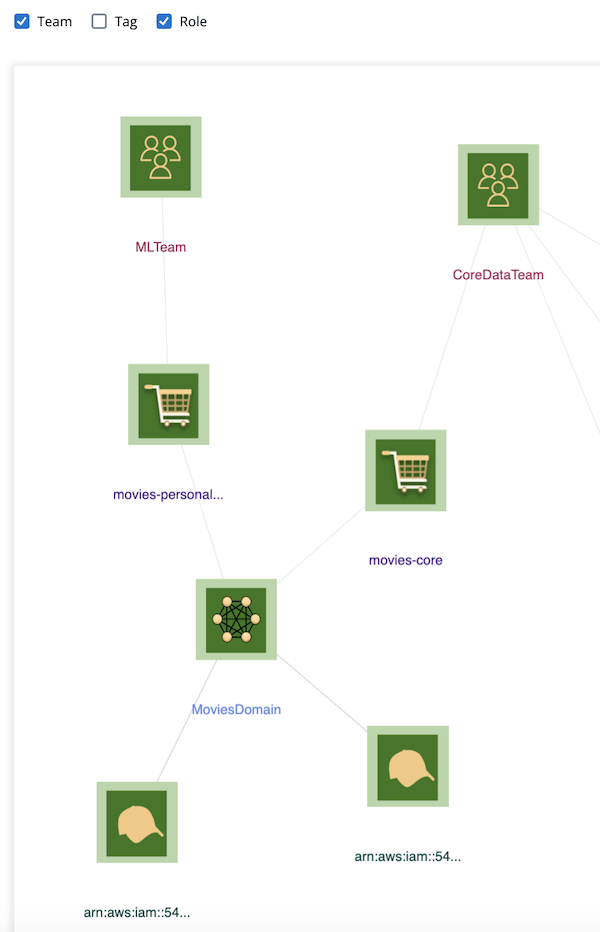
Here is a diagram of the reference ML use case we start with and the Data Mesh entities, such as data products, domains, teams, and roles, that we view at the end of the tutorial:
ML Use Case:
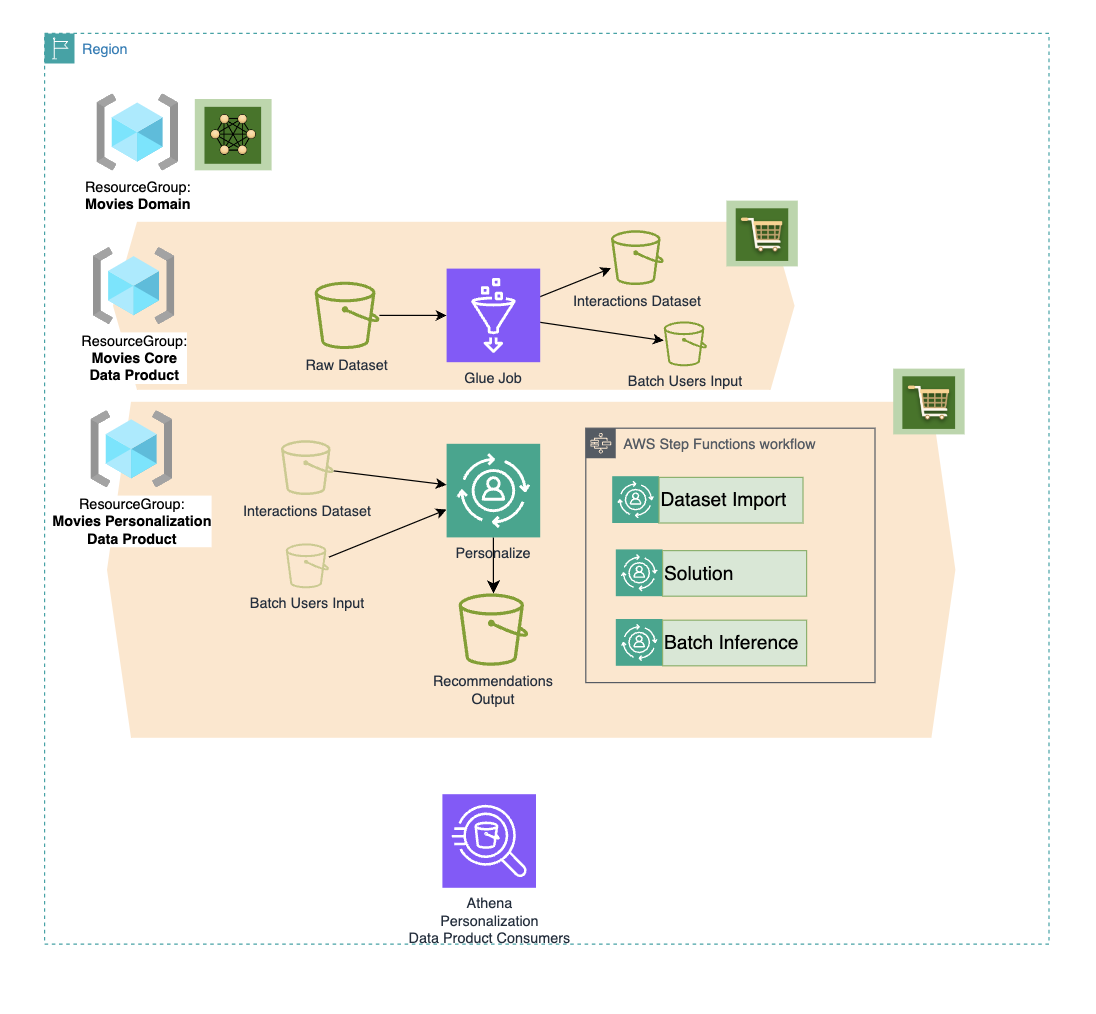
MeshLens View:
Prerequisites
- Complete onboarding for the account and region you will be using to run the tutorial.
- Create the ML orchestration resources as outlined by the reference walkthrough: Create a batch recommendation pipeline using Amazon Personalize with no code
MeshLens Metadata
Next, we will prepare the metadata for MeshLens integration. At the high level, this includes the following:
- Create mappings from datasets to crawlers to data products as outputs.
- Add data quality checks.
- Define input, output, and roles for datasets on input/output resources.
- Define data products and domains as resource groups.
Crawlers
In this section, we will create Crawlers for S3 datasets to bring them into Glue as tables.
Tip
S3 datasets needs to be brought into Glue as tables with crawlers to use them as MeshLens entities. For production workloads, you would be using Cloud Formation templates to define these. We illustrate this in our CFN stack, which you can find here.
- Navigate to AWS Glue console
- Create a database called
movies - Create a crawler named
RawItemInteractions- Add Tags (
Key=Value)meshlens:data-product=movies-core
- Add a data source with S3 bucket location
raw/ - Choose the same IAM role for Glue create in reference the walkthrough
- Database:
movies
- Add Tags (
- Create a crawler named
ItemInteractionsDataset- Add Tags (
Key=Value)meshlens:data-product=movies-core
- Add a data source with S3 bucket location
transformed/interactions/ - Choose the same IAM role for Glue create in reference the walkthrough
- Database:
movies
- Add Tags (
- Create a crawler named
BatchUsersInput- Tags (
Key=Value)meshlens:data-product=movies-core
- Add a data source with S3 bucket location
transformed/batch_users_input/ - Choose the same IAM role for Glue create in reference the walkthrough
- Database:
movies
- Tags (
- Create a crawler named
RecommendationsOutput- Tags (
Key=Value)meshlens:data-product=movies-personalization
- Add a data source with S3 bucket location
curated/ - Choose the same IAM role for Glue create in reference the walkthrough
- Database:
movies
- Tags (
- Run all crawlers and make sure all tables appear under the
moviesdatabase. Should look like this:
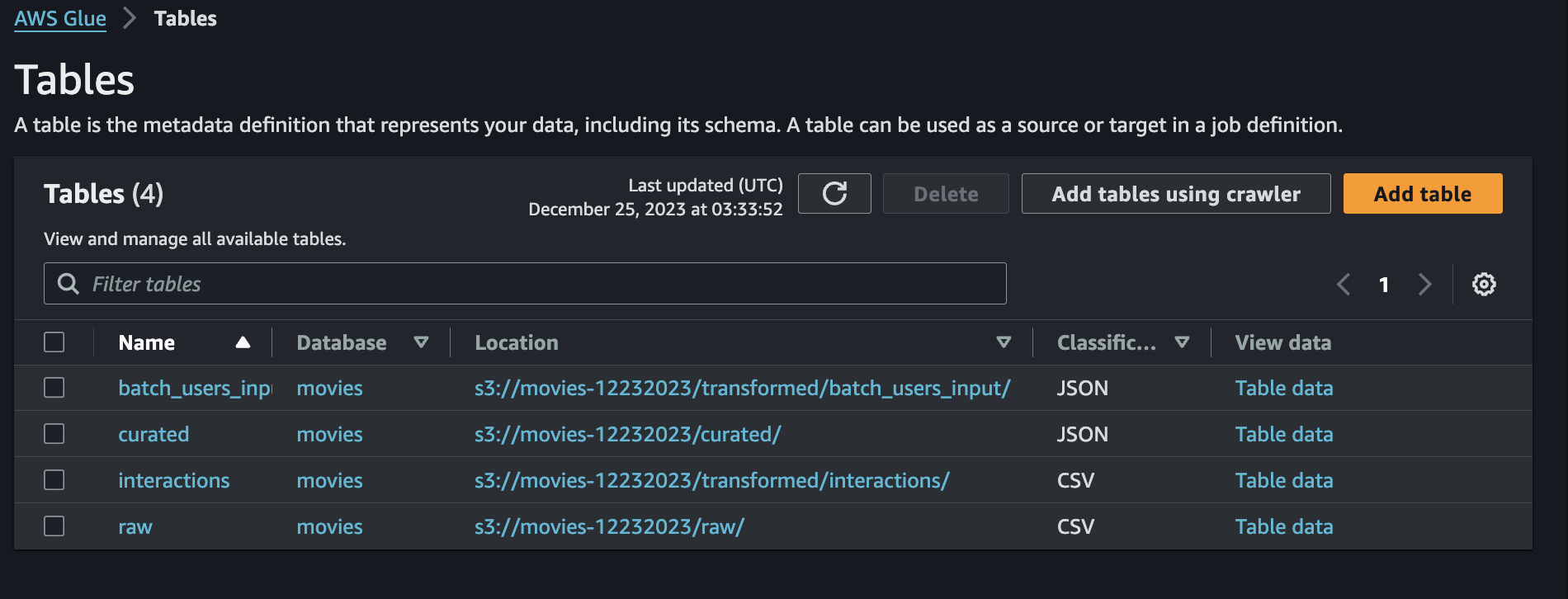
Data Quality
Repeat the following steps for all Glue tables under movies database:
- Navigate to AWS Glue → Table → Data Quality → Create data quality rules
- Pick the service role create in the reference walkthrough
- Recommend rules → Save recommended ruleset → Run ruleset
Input/Output Resources
- Navigate to AWS Glue Console → ETL jobs
- Find the ETL job you created in the reference walkthrough which transforms raw interactions to datasets
- Go to Job Details → Advanced Properties → Tags
- Add tags (
Key=Value)meshlens:data-product=movies-coremeshlens:source:0=RawItemInteractionsmeshlens:output:0=ItemInteractionsDatasetmeshlens:output:1=BatchUsersInput
- Navigate to AWS Step Functions Console → State Machines
- Find the state machine you created in the reference walkthrough
- Go to Tags tab
- Add tags (
Key=Value)meshlens:data-product=movies-personalizationmeshlens:source:0=ItemInteractionsDatasetmeshlens:source:1=BatchUsersInputmeshlens:output:0=RecommendationsOutput
Resource Groups
-
Create Movies Core Data Product
- Select Tag based resource group
- Resource types:
AWS::Glue::JobAWS::Glue::CrawlerAWS::StepFunctions::StateMachine
- Tag filters (
Key=Value)meshlens:data-product=movies-core
- Group Tags (
Key=Value)meshlens:domain=MoviesDomainmeshlens:team=CoreDataTeammeshlens:data-product=selfmeshlens:data-product:quality-threshold=8meshlens:data-product:shelf-life=7
- Name:
movies-core - Select Preview group resources, confirm.
-
Create Movies Personalization Data Product
- Select Tag based resource group
- Resource types:
AWS::Glue::JobAWS::Glue::CrawlerAWS::StepFunctions::StateMachine
- Tag filters (
Key=Value)meshlens:data-product=movies-personalization
- Group Tags (
Key=Value):meshlens:domain=MoviesDomainmeshlens:team=MLTeammeshlens:data-product=selfmeshlens:data-product:quality-threshold=7meshlens:data-product:shelf-life=2
- Name:
movies-personalization - Select Preview group resources, confirm.
-
Create Movies Domain
- Select Tag based resource group
- Resource types:
AWS::ResourceGroups::Group
- Tag filters: (
Key=Value)meshlens:domain=MoviesDomain
- Group Tags (
Key=Value):meshlens:domain=self
- Name:
MoviesDomain - Select Preview group resources, confirm.
MeshLens Catalog
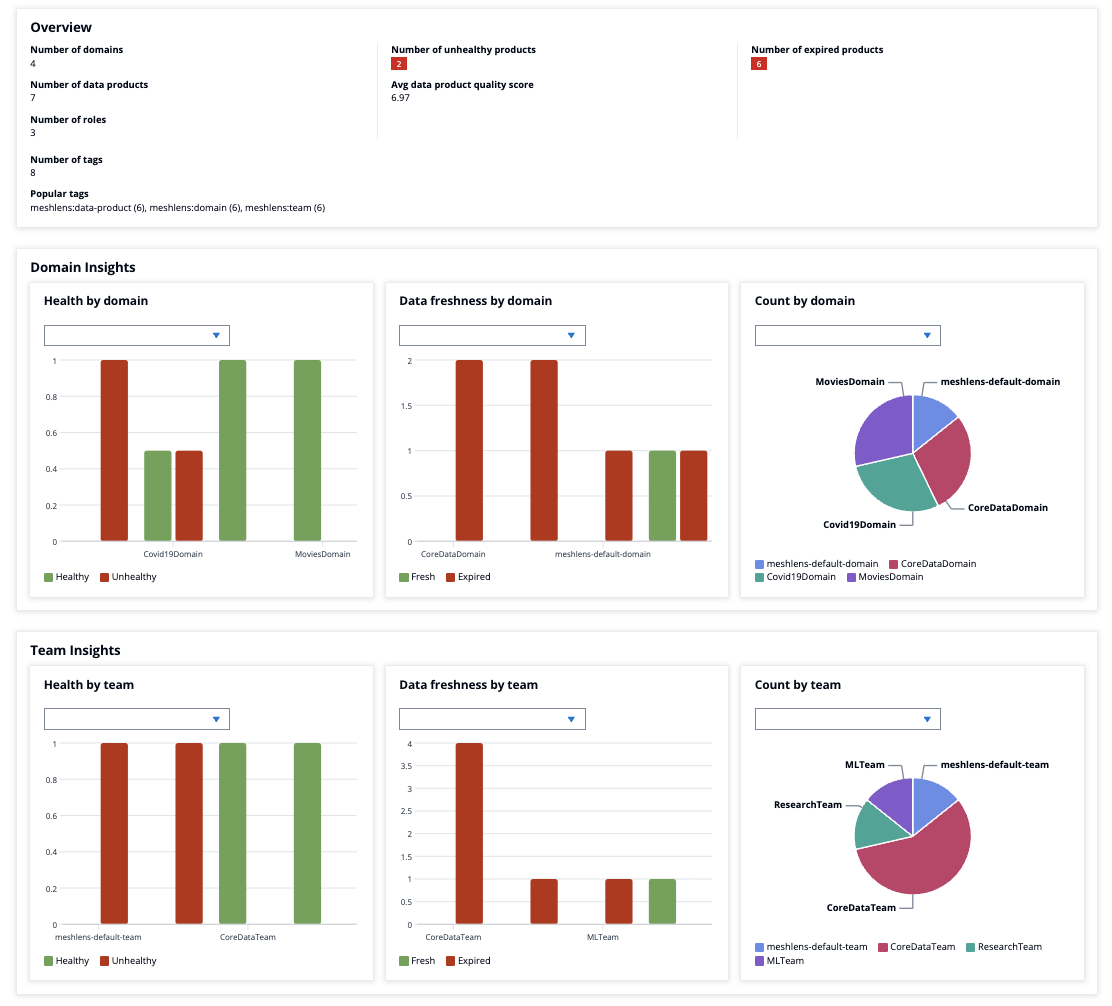
We can now see our integrated metadata displaying insights in MeshLens catalog.
Dashboard
Navigate to /
Table
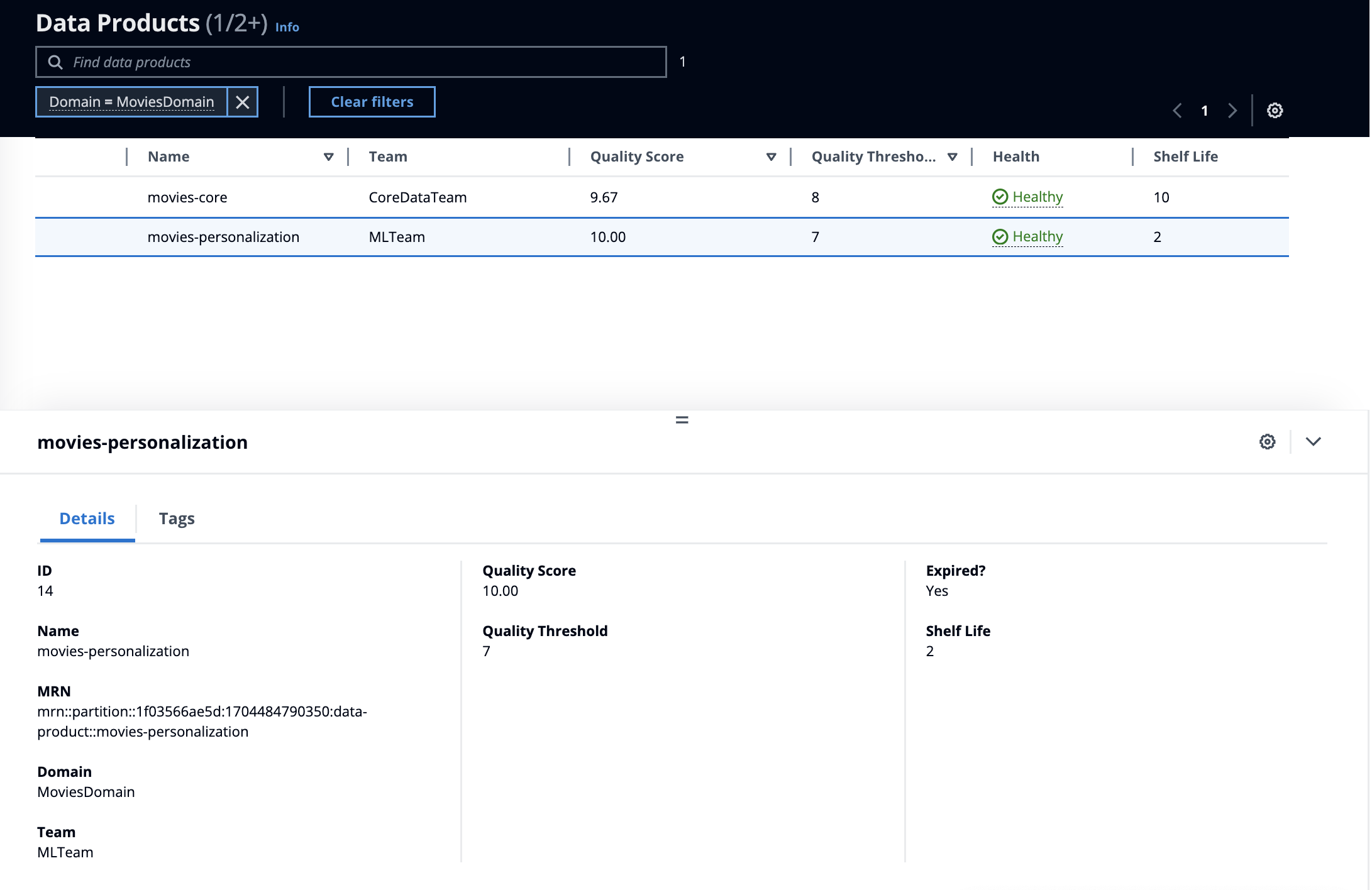
Navigate to /dataProducts
Graph
Navigate to /mesh. Select Team and Role entities, zoom into the Movies Domain.
Data Product Details
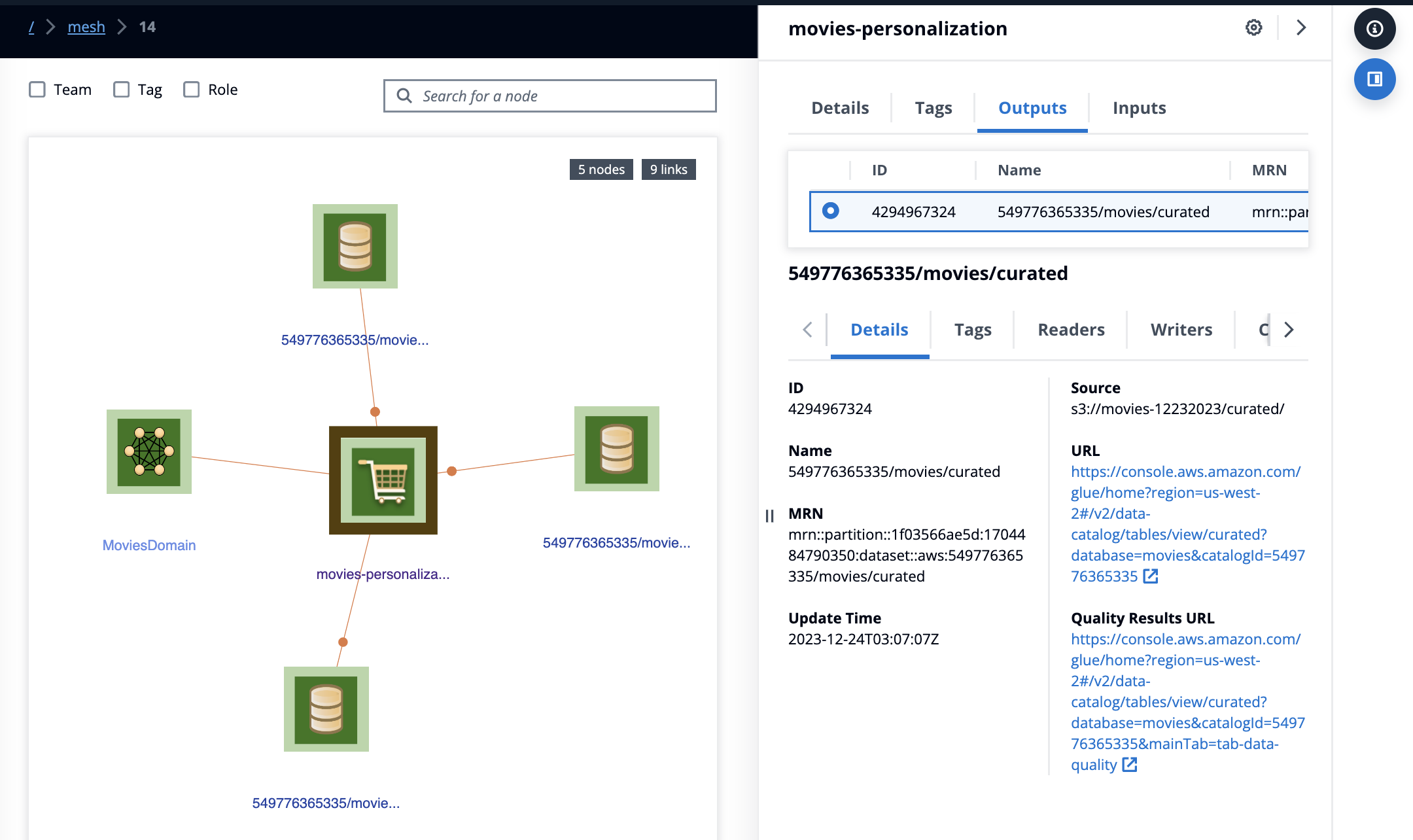
Click on the movies-personalization data product or select it from the search box. The view will switch to showing “neighbors” of the data product and the detail pane will load the properties. Select Outputs tab. To view the details of curated dataset, select it from the list.
Dataset Outgoing Impact Path
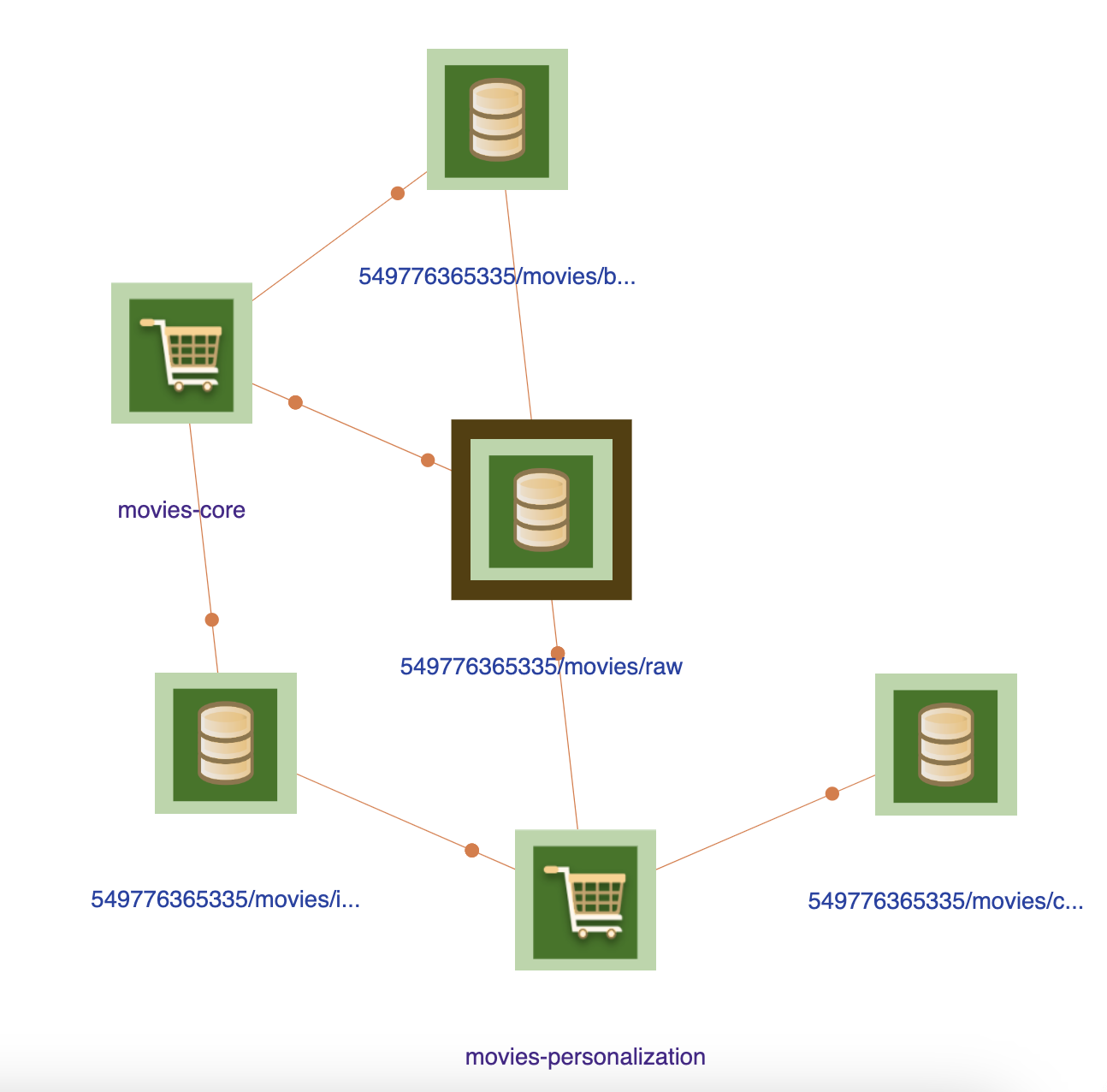
Select movies/raw data from the search box. The view will switch to showing “outgoing path” for the dataset.
Tip
This view can be used to identify all impacted entities when there is an issue with a dataset.
👏 Congratulations, you completed the ML Data Products tutorial of MeshLens!