Tagging
MeshLens builds the entities and their relations by querying metadata APIs in your AWS accounts. However, as customer you need to add some additional information in some resources by tagging them with Data Mesh specific identifiers. For example, to indicate that they are associated with a data product. The following sections guide you through using MeshLens tag taxonomy to add these associations.
Note
If these tagging are missing, MeshLens will assign them to the built-in default resources.
Tip
Example code blocks shown here can be found in the Cloud Formation template that we used before in setting up the Simulation Account.
Taxonomy
-
meshlens:data-product: Used for associating a resource with a data product. Value is a string indicating the name. -
meshlens:[source|output]:[0-n]: Used for indicating source or output dataset to a data product. The value should be the name of the Crawler that processes it. If there are multiple of them listed in the same tagging group, index them starting with 0 and incrementally. This tag is processed only if there exist alsomeshlens:data-productin the resource.
Tip
If the resources in the same Cloud Formation template, it is recommended to use !Ref intrinsic function to reference them instead hard coding the name in tagging.
Resource Types
When tagging resource, there are two resource types which defines what tags are applicable.
- Output only resource: These resources imply output only. When tagged with
meshlens:data-product, associated datasets are output of the specified data product. e.g. Glue Crawler - Input/Output resource: These resources need to explicitly define source and output. For example a Glue Job for batch pipelines or Step functions for ML pipelines. The roles associated with these resources map as “readers/writers” of the datasets.
Output Only Resources
Tagging AWS::Glue::Crawler
When a Glue Crawler resource is tagged with meshlens:data-product, the tables added with the crawler are assigned to the data product as output datasets.
For example, in the following Cloud Formation block we are tagging Covid19Aggregated crawler resource with meshlens:data-product to associate it with covid19-world data product with Ref intrinsic function and Covid19WorldDataProduct resource as parameter.
Input/Output Resources
Supported input/output resources are as follows:
We are showing Glue job tagging as example below. Similar rules apply for all input/output resources.
Tagging AWS::Glue::Job
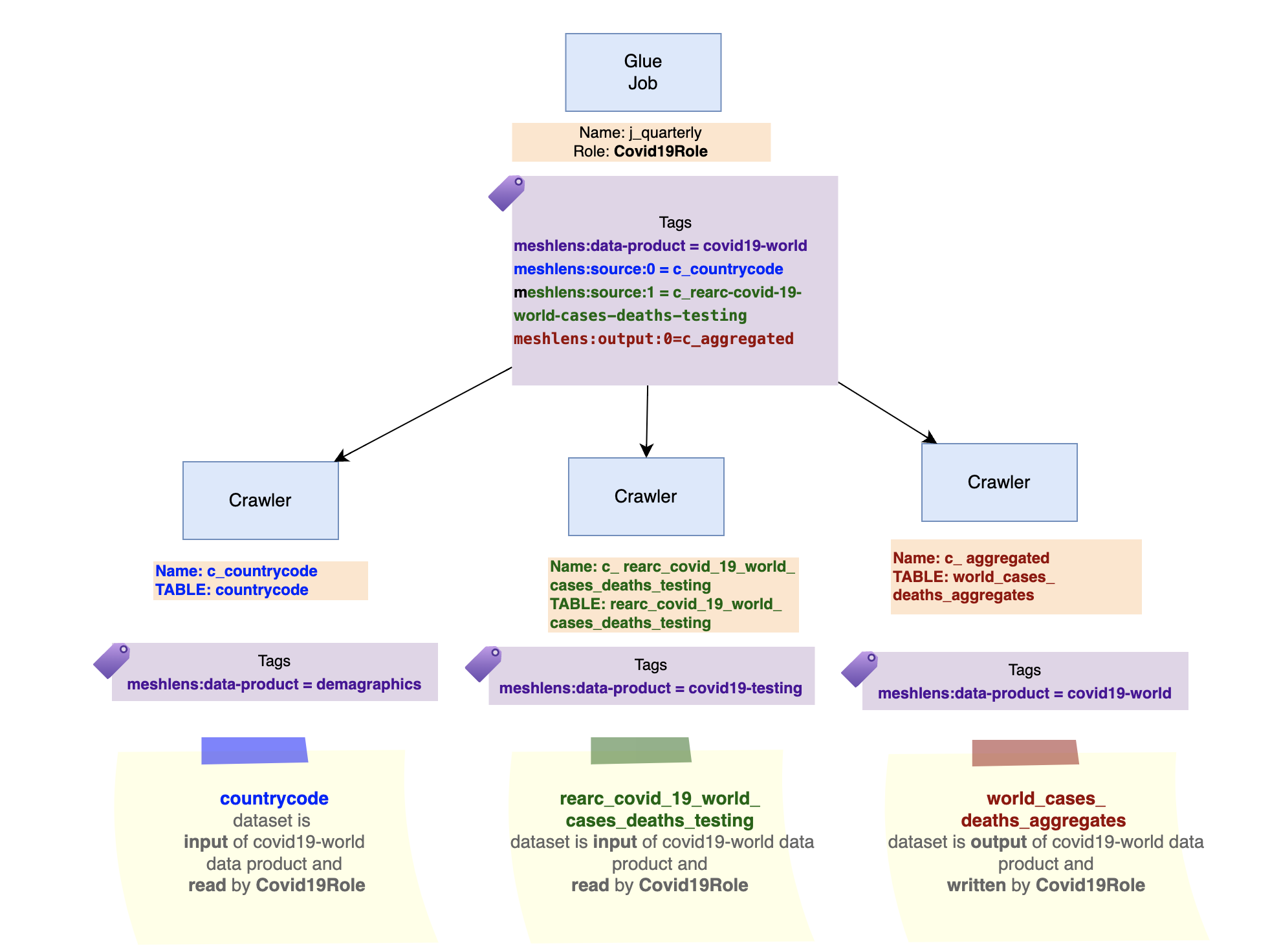
When a Glue Job resource is tagged with meshlens:data-product it allows sources and outputs of the job to be associate with a data product. By adding tags meshlens:source:[0-n] and meshlens:output:[0-n] with values indicating the related crawler, the mapping to the datasets via Glue Tables are created. In addition, job's role are marked as reader and writer of the data product that the dataset belongs to.
In the example below, the datasets linked to Countrycode and RearcCovid19WorldCasesDeathsTesting are sources of the data product referenced by Covid19WorldDataProduct. The job roles of Covid19AggregatorMonthly and Covid19AggregatorQuarterly are “readers” of Countrycode and RearcCovid19WorldCasesDeathsTesting.
Similarly, the dataset linked to Covid19Aggregated is output of the data product referenced by Covid19WorldDataProduct. The job roles of Covid19AggregatorMonthly and Covid19AggregatorQuarterly are “writers” of Covid19Aggregated.
Note
While there are two different ways to map a dataset to a data product as output, one via crawler one via job tagging, the role association as “writer” only happens for the job tagging.
The following diagram illustrates the input/output and reader/writer assignments.